看板 Stock
作者
標題 Re: [新聞] OpenAI:已掌握DeepSeek盜用模型證據
時間 Thu Jan 30 07:26:03 2025
作者
標題 Re: [新聞] OpenAI:已掌握DeepSeek盜用模型證據
時間 Thu Jan 30 07:26:03 2025
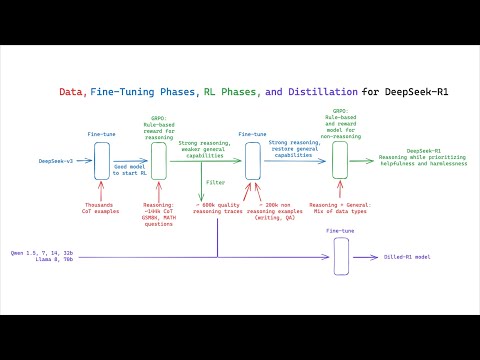
以下部分資訊來自於Reddit anitakirkovska文章的翻譯
LDPC哥哥講到一個重點
Reinforcement Learning =/= Reinforcement Learning from Human Feedback
這也是R1為什麼爆紅的原因
https://imgur.com/lunsvb2.jpg
![[圖]](https://imgur.disp.cc/43/lunsvb2.jpg)
GPT-4最強的地方是他有了某方面的"思考鍊"
(chain-of-thought) 也就是能做出更靈活更準確的推理
但OpenAI是怎麼做出來的並沒有公開,而Deepseek R1是直接公布出來
圖裡面的縮寫全名如下
Cold start data: 最低限度標記的資料集合,讓模型更好理解任務
RL: Reinforcement Learning 模型透過評分獎勵來學習正確答案以及思考邏輯
RLHF = 用人工審查,所以才有當初Google要員工去餵Bard的新聞
SFT: Supervised fine-tuning 用標記的資料去訓練模型讓他在特定領域中更精準
Rejection sampling: 模型產出多個結果的時候選擇特定滿足標準的輸出
其實其他部分都差不多,但Deepseek是用什麼方式去壓低成本去做Pure RL?
用他們自己研發的Gpro (Group Robust Preference Optimization)
https://arxiv.org/abs/2405.20304
[2405.20304] Group Robust Preference Optimization in Reward-free RLHF Abstract page for arXiv paper 2405.20304: Group Robust Preference Optimization in Reward-free RLHF ...
他們怎麼不透過人工去確定產出優劣?
邏輯就是建立最佳猜測的模型: Coherence, Completeness, Fluency
但這也帶來另外一個缺點
就是poor readability (閱讀性差)、language mixing(語言混和)
所以Deepseek用第一張圖的方式去解決
Cold start data處理易讀性
用RL+Rejection sampling+SFT反覆驗證計算並Fine tune 結果
但R1背後的意涵,其實是RL能讓小模型在專精領域出頭天
透過Distill然後微調RL內容,可以在專精領域如藥物、材料...等取得更好的成果
而不用再被綁死於大型語言service provider的服務
而這個也帶來一個影響
企業在AI應用上會更有彈性,同時AI實際應用的穿透性更高
https://tinyurl.com/ms2vev4s
AI research team claims to reproduce DeepSeek core technologies for $30 — relatively small R1-Zero model has remarkable problem-solving abilities | Tom's Hardware
![[圖]]() PhD-candidate Jiayi Pan led a team at UC Berkeley that reproduced the core technology of DeepSeek R1-Zero for just $30, showing how AI could become af ...
PhD-candidate Jiayi Pan led a team at UC Berkeley that reproduced the core technology of DeepSeek R1-Zero for just $30, showing how AI could become af ...
![[圖]](https://cdn.mos.cms.futurecdn.net/zfDV4Yc5qbdYxR9jC8U8NA-1200-80.jpg)
R1背後的邏輯和技術,用在小模型上面有極大的成本優勢
大型語言的發展依然會持續,但硬體算力軍備競賽的資本投入勢必會減少
因為大型語言還是適合多數小白使用者 (如我)
以GPT-4來說,他給的回答訊息會很完整包括前因後果
而R1給的就是非常簡潔.....不太廢話
對專業人士來說,R1有時候只給你一行字其實非常的有效率
但智障如我就必須要花更多時間去思考
BTW R1在Ethical Considerations 上面多數人評價是比GPT4還好喔XDDDD
看到這東西,反正是開源的,程式碼都攤開在那邊給你看
應該是要想著怎麼去利用,而不是討論中/美或成最大贏家嗎?
怎麼搞到變成政治意識形態的爭執了?
有些推文一直扯到超導體,我就不懂有什麼可比性...
本身有一點點計算機概論底子加上英文能力就可以去稍微理解這東西
結果很多人都只用台灣媒體或網紅的貼文去判斷,這個邏輯不太行阿
※ 引述《LDPC (Channel Coding)》之銘言:
: 現在全網路上的開源數據資料是屬於pre-training端 大多都是野生數據 無標籤
: 那東西只是讓模型去向鸚鵡一樣 去做文字接龍
: 但第二階段訓練會用到RLHF (Reinforcement Learning from Human Feedback)
: 就是要人類針對不同數據給意見 這個是要給標籤
: 所以你才會聽到狗家之前要求全公司員工去給意見讓Gemini前身 Bard 去做人類feedback
: 這個人工成本是很大
: Deepseek-R1跟大家說 我們不用人類給的feedback了 我們可以免除這塊
: 大家都在討論的叫做sythetic dataset
: 這個步驟是來自於你有許多野生數據 但需要加上標籤 那標籤可以拿更強大模型來標註
: 比方說 一道數學題目 你可以用人類寫解答 或者要拆步驟 每步驟讓gpt-4o寫個答案
: 這就是所謂synthetic dataset 然後用這組數據去調教模型 這步驟會決定
: 你的模型多智能 這過程就是call api 現在ai界都這樣幹 缺點就是訓練模型上限就是
: 原始母模型 這跟傳統蒸留 用模型直接交模型不太依一樣
: 這種方式就是可以用低成本 接近gpt-4o 但你如果這樣幹 你模型就不能商業化
: 頂多發表到文章 講你這是怎樣做 最經典例子就是LLaVA那篇 講如何用gpt4o
: 產生sythetic dataset讓textLLM 變成多模態 直接打爆其他大廠高成本多模態
: 之前網路上已經有人在討論 到底deepseek有沒有用api去合成數據
: https://reurl.cc/A6ab98
: https://x.com/bboczeng/status/1883374489519698413 (zero是r1第一版)
: 在training這部分還沒定案之前 大家就先吃瓜看看吧 @@
: 但這思路還是有可取之處 就是模型教模型 不要再用人類RLHF去教模型
: https://x.com/op7418/status/1884065603184681162
: 這有點像回到當年alphago那條路線 模型互相教
: 下面網址是第三方 大家要複製deep-seek R1開源計畫 任何人想參加都可以
: https://huggingface.co/blog/open-r1
: 目前公認是dep-seek R1隱藏了
: Replicate the R1-Distill models by distilling a high-quality
: reasoning dataset from DeepSeek-R1.
: 上面專案在徵求大家嘗試去製造出合成數據
: 好了 我要去炸薯條了 @@/ 救救我
: ※ 引述《IBIZA (溫一壺月光作酒)》之銘言:
: : 各家互相參考, 指的是訓練方法還有訓練的文本挑選, 蒸餾不太一樣
: : AI = 模型的程式碼+訓練
: : 能開源的部分只有程式碼, 訓練是看各自調教
: : 模型的能力夠, 差不多的調教方式就會得到差不多的結果
: : 訓練方法更好, 或是文本品質越高、越多樣、量越多, 模型就越強
: : 自從OpenAI爆紅以來, 大公司的LLM模型都是遵循OpenAI的訓練方法
: : 預先訓練: 拿大量文本讓AI模型學習基本語言能力、基本知識
: : 監督微調: 有了基本能力之後, 模型開始有推理能力
: : 這時候由人類介入, 告訴模型怎麼想是對的, 怎麼想是錯的
: : 之前所謂的貼標籤, 就是這個階段
: : 獎勵建模: 把對錯的判斷建立模型, AI想對了, 這個模型就獎勵他
: : 強化學習: AI自己跟自己練習
: : 不管是meta還是google, 之前都是照OpenAI這個成功模式做
: : 所以這些公司能做的就是拚算力, 透過更大量的訓練, 希望最終可以暴力超車
: : 但蒸餾就不同, 蒸餾是直接拿另一個模型的推理結果, 讓另一個模型照著得到同樣結果
: : 譬如我要我剛剛問ChatGPT, 要他給舉例說明什麼是擬人法
: : 他的回答是這樣
: : https://i.imgur.com/ey5mX61.png
: : ChatGPT要回答這個問題, 中間要經過很多推理, 譬如他要先理解我的問題
: : 這裡面就牽涉到, 他要理解我講的擬人法是修辭當中的擬人法
: : 然後再從這一個理解, 去思考擬人法的意思是甚麼, 最後再想出一個符合範例
: : 蒸餾的話, 就是學生模型已經預先知道這個問題的答案是甚麼
: : 有頭有尾, 要生出中間的推理就會比較容易
: : 但這裡有個問題
: : 你要用蒸餾讓一個模型得到另一個模型類似的能力
: : 通常就是需要老師模型產生極大量的練習後結果
: : 才能傳授畢生功力給學生模型
: : 如果ChatGPT是開源模型, 可以自己部署在自己平台上
: : 要做這樣大規模訓練是有可能
: : 但ChatGPT無法部署在自己平台
: : (剛剛有人說ChatGPT 2可以, 但蒸餾頂多只能逼近老師, 用ChatGPT 2只能蒸出垃圾)
: : 所以要做蒸餾只能透過API, 而要透過API做幾千萬甚至幾億規模的蒸餾訓練
: : 這難度極高啊....
: : (ChatGPT剛剛教我另一個方法
: : 就是拿一個原本就有ChatGPT4能力的模型
: : 這樣只要少量訓練, 就能超越ChatGPT 4
: : 但原本就有ChatGPT 4能力的新模型難道自己會生出來嗎XD
: : 你還是得先得到這個模型啊...就是V3
: : 那V3怎麼來?)
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 1.163.78.138 (臺灣)
※ 作者: zzahoward 2025-01-30 07:26:03
※ 文章代碼(AID): #1dchaFQv (Stock)
※ 文章網址: https://www.ptt.cc/bbs/Stock/M.1738193167.A.6B9.html
※ 同主題文章:
01-29 21:37
01-29 21:38
01-29 22:38
01-29 23:20
01-30 01:19
01-30 01:49
01-30 02:44
Re: [新聞] OpenAI:已掌握DeepSeek盜用模型證據
01-30 07:26
01-30 08:59
01-30 09:08
01-30 10:18
推 : 消息一堆,但我只相信真金白銀交易的投資人,看這三天NV, tsmc adr 股價就知道了1F 01/30 07:35
推 : 青鳥:DS有沒有台灣價值,沒有就是垃圾3F 01/30 07:46
![[圖]](https://i.imgur.com/2TppMS1h.png)
推 : 少年股神:崩盤時就是世界末日5F 01/30 07:48
→ : 小模型套完是真的會變強的6F 01/30 07:48
推 : 開盤會跌多少7F 01/30 07:49
推 : 推 結論8F 01/30 07:50
→ : 台灣人素質比美國人爛多了
reddit一堆專業文
台灣人只會在那邊64
笑死
還什麼破解言論審查 的it大臣也能上新聞lol9F 01/30 07:51
reddit一堆專業文
台灣人只會在那邊64
笑死
還什麼破解言論審查 的it大臣也能上新聞lol9F 01/30 07:51
推 : 驗證台灣媒體這次一半以上都是垃圾14F 01/30 07:53
→ : 各國的論壇看一看
台灣論壇素質跟回教國家差不多15F 01/30 07:53
台灣論壇素質跟回教國家差不多15F 01/30 07:53
而且我本身也沒完整的專業知識,所以也只能Distill? XD
但整串看下來,有些人連distill都不會.....
→ : 回教社會 隨便一個文章都能扯到 宗教對抗
台灣是隨便一個文章都能扯到抗中保台
北七19F 01/30 07:54
台灣是隨便一個文章都能扯到抗中保台
北七19F 01/30 07:54
GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
![[圖]]() Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub. ...
Fully open reproduction of DeepSeek-R1. Contribute to huggingface/open-r1 development by creating an account on GitHub. ...
推 : 這篇算完整,但股版講這麼細喔,我前幾篇都沒講想說真的有人會想看嗎24F 01/30 07:55
→ : DS 的技術當然是真的,對開發LLM和推理模型也很有幫助,但也確實蠻有可能在中間用到ChatGPT 的生成去26F 01/30 07:56
→ : 台灣是說你五毛粉紅支那
回教是說 你真主阿拉的叛徒
笑死28F 01/30 07:56
回教是說 你真主阿拉的叛徒
笑死28F 01/30 07:56
→ : 微調,美中如何出手和股市息息相關 誰說不重要,這是股板31F 01/30 07:56
推 : 大的搞的了小的,小的搞不了大的,有沒有可能以後一個星門就可以解決所有問題?33F 01/30 07:57
推 : 看了一下gpro原來是ppo的變化型 本來需要一個等同模型規格的actor變成分組驗證 在網路上一直搜尋新的輸出讓RL準確性更高36F 01/30 07:59
推 : 台灣就是文組誤國啊 理組負責賺錢給文組亂花39F 01/30 08:00
→ : 上面文章分析很好,兩者間不影響繼續資本支出40F 01/30 08:01
推 : 推這篇41F 01/30 08:01
推 : 高佳魚學姊委員就是猛打中國造假 還上YAHOO頭版42F 01/30 08:02
推 : 推43F 01/30 08:06
推 : 這邊就是低能網軍互打,期待啥素質44F 01/30 08:07
推 : 經過這次事件才知道台灣很多人很有勇氣 愛搶著出來發文讓大家知道自己沒長腦45F 01/30 08:09
→ : 正常台灣人連假都在日本玩,不然就是計畫出國,在這邊鬼混帶風向要嘛5毛要嘛145047F 01/30 08:09
推 : 嗯嗯跟我想的差不多(?49F 01/30 08:10
推 : 推50F 01/30 08:11
推 : 討論到這答案大概也揭曉了 gpro是關鍵 但是跟RLHF相比 大概只有數理這種答案對錯很明確的問題吃香
玩agi不小心玩出edge的未來趨勢?哈51F 01/30 08:11
玩agi不小心玩出edge的未來趨勢?哈51F 01/30 08:11
→ : 沒發現多數心得只有兩種嗎。5毛:中國超強。1450:中國製不可信54F 01/30 08:12
推 : 標準 股板 無用文56F 01/30 08:13
→ : 看台灣的評論 會覺得DS是假貨 一堆假專家57F 01/30 08:14
推 : 推,做股票還在意識形態根本就找死而已,當然是看哪邊有利就壓哪邊58F 01/30 08:18
→ : distillation不是微調啊,會有爭議的是他拿別人的大模型來當他自己的訓練
MoE也不是新概念,其實OpenAI和Gemini裡面都是60F 01/30 08:19
其實很多小模型都用別人的模型來訓練阿 然後Distillation應該是指V3的部分?MoE也不是新概念,其實OpenAI和Gemini裡面都是60F 01/30 08:19
但V3本身是"Nothing",R1對V3的演算法才是重點
V3水準一堆開源都做得到
推 : 樓上沒看解說齁?r1是蒸餾自己的model欸63F 01/30 08:21
→ : 結論是他們很有效率的用其他人的模型為輔助產生了新的模型,這對於很多新進廠商很有幫助64F 01/30 08:22
推 : 不懂又愛鬼扯太多,跟舊版chatgpt一個德行66F 01/30 08:23
→ : 誰跟你說他只有蒸餾自己的model?67F 01/30 08:23
推 : 推68F 01/30 08:24
推 : 看不懂的跟我去洗碗就好惹69F 01/30 08:25
→ : 應該說很多不太懂的人在討論可不可能盜用ChatGPT,都是以完全蒸餾的前提,這前提就錯了,有盜用的話,可能只有部分用到gpt的生成,例如起頭或收尾70F 01/30 08:26
推 : 你自己說更多企業能夠自行建置自家的AI 又說硬體需求會減少? 供三小73F 01/30 08:29
因為算力需求等級不同啊 小模型專精領域+RL不需要那麼多硬體那個是等比級數的差異
推 : 台灣很多人沒在思考的75F 01/30 08:29
推 : 推,進步的人去學習理解,而不是降階成意識政治戰爭76F 01/30 08:30
推 : 幫推 程式碼都開源了 不嘗試去驗證它 找投資機會
整天在那邊中國一定是假的 這樣會賺錢嗎78F 01/30 08:31
整天在那邊中國一定是假的 這樣會賺錢嗎78F 01/30 08:31
推 : 因為台灣就只剩下意識形態了80F 01/30 08:33
→ : R1應該是MoE版的V3,並不是V3 distallation81F 01/30 08:34
→ : 但V3其實一堆開源都做得到了 V3非常不怎樣82F 01/30 08:35
→ : 在這種算法開放的環境裡,算法重要厲害但不值錢,除非你直接屌打,搶走所有市佔,因為大家都高手,幾個禮拜內就能把你算法抄走了,倒頭來拼最強還是要拼算力83F 01/30 08:36
推 : 這又不衝突 算力需求的減少 導致大公司不需要再買那麼多晶片 但成本下降也讓中小公司可以進入 一個加項 一個減項 誰比較多就看判斷 我跟原po都是認為減項更大點 但不是一個因素永遠只會影響一個方向好嗎 思考別太狹窄87F 01/30 08:36
因為不是每間公司都需要超高算力去瞬間得到結果小模型的service provider會蓬勃成長是真的
→ : 程式碼沒有開源啊,有的話連結給一下
只有model和inference的放出來92F 01/30 08:37
只有model和inference的放出來92F 01/30 08:37
→ : 還有資料94F 01/30 08:37
推 : 能幫助我的工作就是好工具95F 01/30 08:38
推 : 還好還有正常人 但你講這麼多 井蛙還是只會呱呱96F 01/30 08:41
推 : github有人在試著重建阿d大可以去幫忙97F 01/30 08:41
→ : 那就不是他開源啊,你在講啥?98F 01/30 08:42
多數討論是V3是GPT distillation而不是R1吧,但V3是什麼大家關注的焦點嗎?XDDD→ gn02118620 …
推 : 這篇正解 網軍國家隊這幾天真的很急299F 01/30 17:16
推 : 脆鳥:有比我們添財少女懂嗎?300F 01/30 17:17
推 : 因為是中國研發的,如果是米國的就沒這些問題301F 01/30 18:30
推 : 認真推302F 01/30 19:00
推 : 推303F 01/30 19:11
--
作者 zzahoward 的最新發文:
- #作者: zzahoward (Cheshire Cat) 看板: NBA 要重建當然沒問題,但他們現在喊重建但未來首輪資產很少阿 2025 有兩支 1. 火箭有交換權,目前看來火箭87%一定來換,所 …222F 84推 1噓
![]() 影/新竹嚴重車禍影像曝!34歲女騎士遭高速猛撞噴飛亡 2025-03-01 15:00 聯合報/ 記者 張裕珍 新竹市南大路今天早上發生重大車禍釀1死6傷慘劇,肇事的79歲林姓駕駛開車載妻子行經 南 …153F 72推 24噓
影/新竹嚴重車禍影像曝!34歲女騎士遭高速猛撞噴飛亡 2025-03-01 15:00 聯合報/ 記者 張裕珍 新竹市南大路今天早上發生重大車禍釀1死6傷慘劇,肇事的79歲林姓駕駛開車載妻子行經 南 …153F 72推 24噓![]() 這台車最大的問題其實不是什麼沒有車道置中、中國平台...etc 你要完整Lv2、恆溫加錢就有 後座小? 這本來就是一台4.2m的CUV...後座要怎麼擠出來空間 請舉例一台4.2m級距的車子有良好的 …71F 30推
這台車最大的問題其實不是什麼沒有車道置中、中國平台...etc 你要完整Lv2、恆溫加錢就有 後座小? 這本來就是一台4.2m的CUV...後座要怎麼擠出來空間 請舉例一台4.2m級距的車子有良好的 …71F 30推- 其實我比較好奇的是 Prius HEV系列絕對沒問題,歷史悠久口碑紮實 PHEV系列其實表現也很好,就算不插電也還是台不錯的Hybrid車款 但不插電,PHEV系統就少了很大的優勢了,跟HEV 87 …102F 27推 1噓
- 亂象有解阿 你把持有稅上升、老車持有稅每年繼續往上加就好了 管你兩輪四輪,兩輪牌照稅每年五萬起、四輪每年十萬起 稅收專款專用拿來補貼客運和軌道運輸,路上車子不就少了? 瞬間馬路就空了,路邊停車格流動 …115F 32推 5噓


點此顯示更多發文記錄